Time: 24-48 hours (mostly unattended) • Active setup: 30-45 minutes • Difficulty: Advanced
Already collecting runtime traces? Stream them straight from Postgres with the
runtime_pg data preset (+override /data@_global_: runtime_pg db_url=...) or stick with exported JSONL files (see Runtime Export Guide).Need to customise Hydra configs? See the Training Configuration guide for directory structure and override patterns.Who Should Train Custom Models
You need custom training if you have:- Proprietary knowledge not available in public models
- Domain-specific tasks where generic teaching doesn’t work well
- Regulatory requirements that prevent using pre-trained models
- Extreme performance needs where every percentage point matters
- 4-8 H100 or A100 GPUs (40GB+ VRAM each)
- 2-3 days of training time
- Basic PyTorch and distributed training knowledge
- ~200GB disk space for checkpoints
Training Pipeline Overview
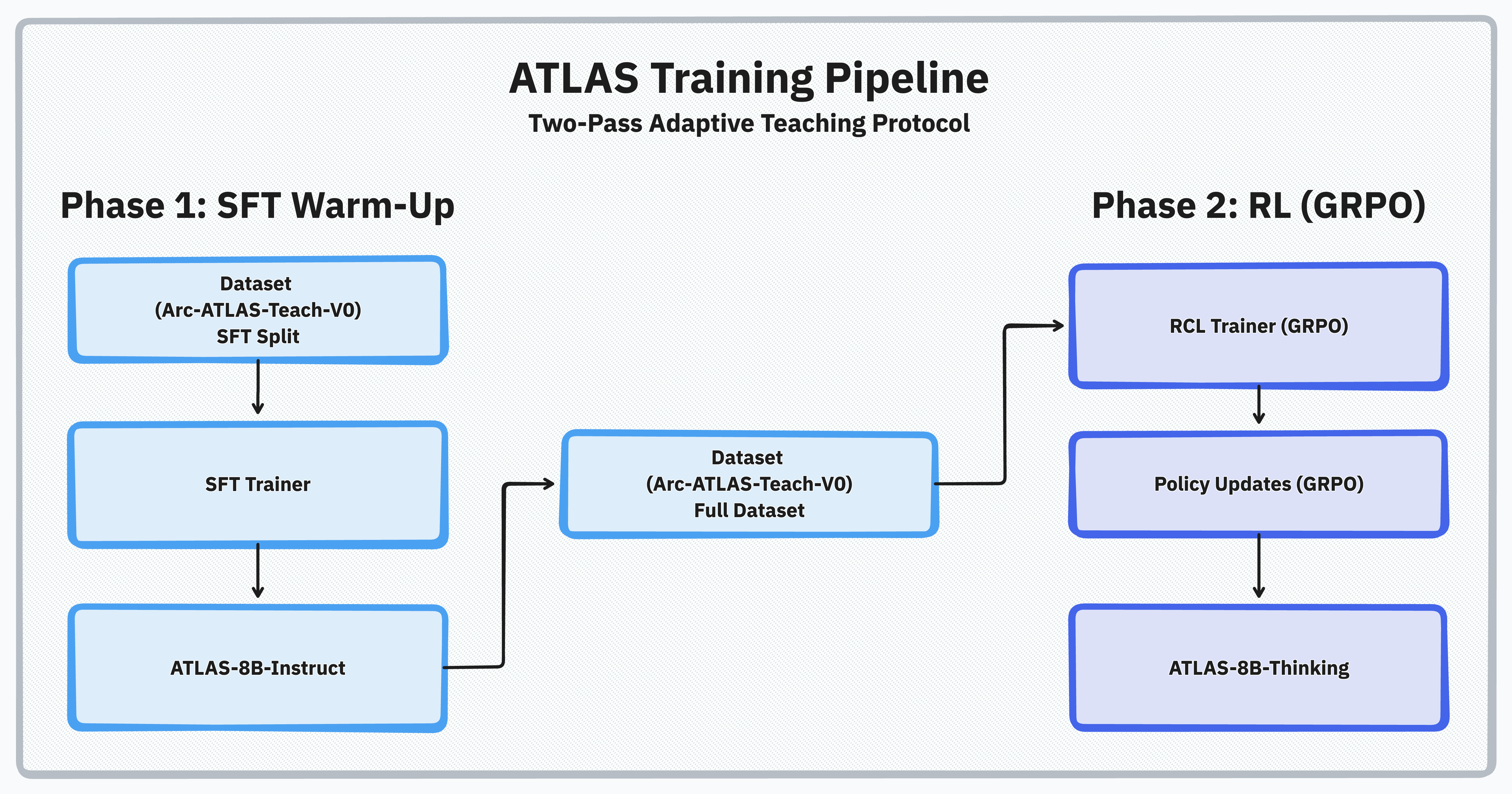
Runtime traces as the data source
Direct database access (SDK v0.1.13+) queries training sessions from PostgreSQL with reward-based filtering and selective data loading. This eliminates JSONL export intermediates and prevents schema drift:Step 1: SFT Warmup
Goal: Establish foundational teaching capabilitiesWhat It Does
Supervised fine-tuning teaches the model basic teaching patterns through demonstration. Think of it like a student teacher observing an expert before trying it themselves.Configuration Snapshot
Run It
Verify Success
Check training is running:| Metric | Target | What It Means |
|---|---|---|
| Training Loss | <1.5 | Model is learning patterns |
| Gradient Norm | <5.0 | Training is stable |
| Duration | 4-6 hours | On 8× H100 GPUs |
Step 2: Launch vLLM Server
Goal: Fast inference for RL trainingWhat It Does
The vLLM server provides high-throughput generation during reinforcement learning. It runs on separate GPUs from the training process for maximum efficiency.Run It
Atlas Core ships a lightweight launcher so you can spin up the inference stack without third-party tooling:scripts/launch_with_server.sh <server_gpus> <training_gpus> src/atlas_core/configs/recipe/teacher_rcl.yaml .... That wrapper orchestrates atlas_core.training.generation.vllm_server under the hood, waits for the health checks to pass, and then launches scripts/launch.sh for reinforcement learning.
Verify Success
Check server health:tensor-parallel-size: Number of GPUs for inference (match your hardware)gpu-memory-utilization: How much VRAM to use (0.9 = 90%)max-model-len: Maximum sequence length (2048 is good default)
Step 3: Run GRPO Training
Goal: Optimize teaching through reinforcement learningWhat It Does
GRPO (Group Relative Policy Optimization) trains the teacher to actually improve student performance. The reward comes from measuring if students get better when taught.Run It
Verify Success
Monitor training progress:-
Reward Mean (chart:
train/reward)- Should trend upward from baseline (~0.3-0.5 → 0.7-0.8)
- Steady increases indicate the teacher is learning effective guidance
-
KL Divergence (chart:
train/kl)- Healthy range: 0.5-2.0
- Warning if >5.0 (policy diverging too far from SFT baseline)
-
Non-degradation Rate (chart:
train/non_degrade_rate)- Target: >95% of samples improve or maintain quality
- Warning if <90% (teaching is making students worse)
| Metric | Healthy Range | Warning Sign |
|---|---|---|
| Reward Mean | 0.3 → 0.8 (increasing) | Plateau or decrease |
| Non-degradation Rate | >95% | <90% indicates issues |
| KL Divergence | 0.5-2.0 | >5.0 suggests collapse |
Key Configuration Parameters
You only need to understand 3-5 core parameters:beta (KL divergence coefficient)
What it does: Controls how much the model can change from the original Default: 0.04 When to adjust:- Model changing too fast? → Increase to 0.06
- Training too conservative? → Decrease to 0.02
temperature (sampling temperature)
What it does: Controls how creative the teaching is Default: 0.7 When to adjust:- Want more diverse teaching? → Increase to 0.9
- Teaching too random? → Decrease to 0.5
learning_rate
What it does: How fast the model learns Default: 5e-7 (much smaller than SFT!) When to adjust:- Training too slow? → Try 1e-6
- Rewards collapsing? → Decrease to 1e-7
Advanced: Reward System Configuration
Advanced: Reward System Configuration
GRPO uses the principle-based reward system. Point to the config:The offline config focuses on helpfulness and process (not accuracy):Monitor
rim_rewards in logs to spot regressions.Advanced: All Parameters
Advanced: All Parameters
Troubleshooting
CUDA Out of Memory
CUDA Out of Memory
Problem: GPU runs out of memory during trainingQuick fixes:
Reward Collapse
Reward Collapse
Problem: Rewards go to zero or negativeQuick fixes:
vLLM Connection Failed
vLLM Connection Failed
Problem: Training can’t connect to serverQuick fixes:
Slow Training
Slow Training
Problem: Training slower than expectedQuick fixes:
Expected Results
After successful training, you should see:Performance Metrics
- Teaching efficiency: 15.7% average accuracy improvement
- Safety: 97% non-degradation rate
- Token efficiency: 50% reduction in response length
- Completion rate: 31% improvement (69% → 100%)
Training Duration
- 2 GPUs: 4-5 days
- 4 GPUs: 2-3 days
- 8 H100s: 24-36 hours
Output Artifacts
Validation
Test your trained model:Performance Optimization
Multi-Node Training
Scale across multiple machines:DeepSpeed for Large Models
Atlas Core uses Accelerate configs (inaccelerate/) to control DeepSpeed settings. Choose one of the shipped presets:
accelerate/deepspeed_zero3.yaml(default)accelerate/deepspeed_zero3_cpu_offloading.yaml(CPU offload)accelerate/deepspeed_zero1.yaml(lighter config)
Next Steps
SDK Runtime
Keep production agents improving between offline runs
Deploy to Production
Integrate your custom teacher into production
Reward System Deep Dive
Understand how teaching effectiveness is measured
References
- Training Data Pipeline - Direct database access for training data
- ATLAS Technical Report - Detailed methodology and ablations
- GRPO Paper - Original algorithm
- vLLM Documentation - Server configuration options
- Export Runtime Traces - Direct database access and JSONL export methods
- Quickstart - Collect runtime traces before training