
What is ATLAS?
ATLAS is a continual learning framework for production LLM agents. It combines runtime quality control with offline reinforcement learning to improve agent reliability, reduce token costs, and build domain expertise through persistent memory. The system layers a dual-agent reasoning loop (student + verifying teacher) on top of any model. The Atlas SDK streams causality traces into Postgres, and Atlas Core (this repository) trains new teacher checkpoints via on-policy distillation (GKD) or reinforcement learning (GRPO).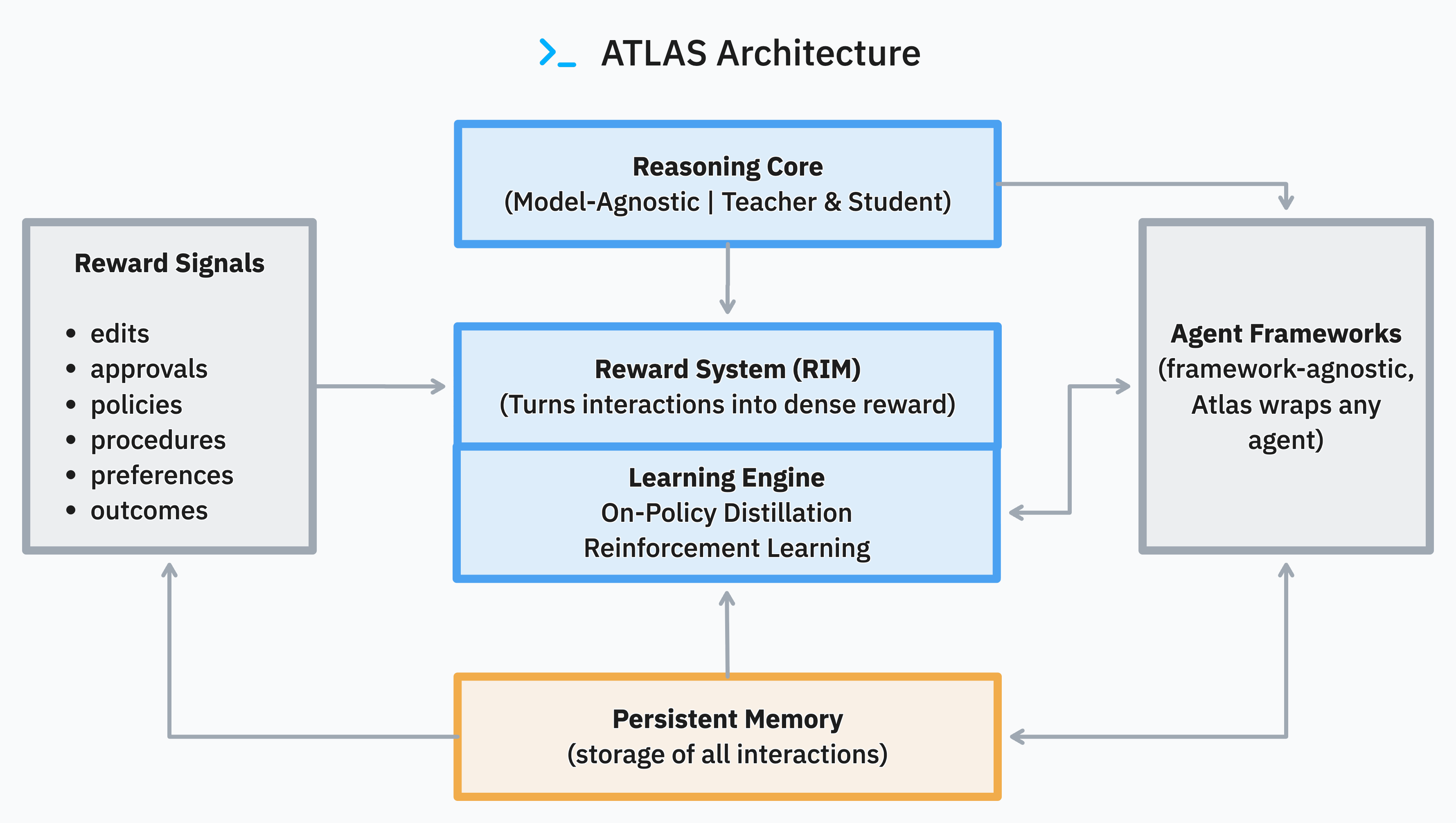
Atlas runtime captures traces; Atlas Core trains improved models from those traces.
Which Repository Do You Need?
Atlas SDK
Use if you want to:
- Run agents with quality control
- Get runtime supervision and retries
- Export traces for later training
pip install arc-atlasStart: SDK QuickstartAtlas Core
Use if you want to:
- Train custom teacher models
- Run GKD or GRPO training
- Fine-tune on exported traces
Why Use ATLAS?
| Benefit | How | Result |
|---|---|---|
| Lower costs | Adaptive supervision allocates reasoning only when needed | ~50% token reduction |
| Higher reliability | Real-time teacher review catches errors before production impact | +15.7% avg task success |
| Continuous improvement | Offline training (GRPO/GKD) updates teacher from production traces | Compounding expertise over time |
Runtime vs. Training: The Atlas SDK handles runtime orchestration and trace export. Atlas Core (this repository) handles offline training (GKD/GRPO).
End-to-End Workflow
| Stage | Run This | Output | Time |
|---|---|---|---|
| Runtime quality control | atlas run | Reviewed traces with reward scores | Minutes |
| Export traces | arc-atlas export | JSONL dataset from approved sessions | Minutes |
| Train teacher (GKD) | atlas-core offline-pipeline | Distilled teacher checkpoint | 4-8 hours |
| Train teacher (GRPO) | atlas-core train recipe@_global_=teacher_rcl | RL-optimized teacher checkpoint | 24-48 hours |
Getting Started: Two Paths
| I want to… | Path | Start Here |
|---|---|---|
| Run tasks with dual-agent orchestration | Atlas SDK | SDK Quickstart |
| Wrap my existing agent in quality-control loop | Atlas SDK | BYOA Adapters |
| Distill traces into smaller teacher | Atlas Core | GKD Training |
| Train from rewards (RL) | Atlas Core | GRPO Training |
SDK Runtime Orchestration
Run your agent with closed-loop learning. Get started in minutes.
Offline Training (Atlas Core)
Convert runtime traces into GRPO/GKD training jobs and ship updated teachers.
Research & Resources
- ATLAS Technical Report (PDF) - Methodology, benchmarks, implementation details
- Arc Research - Latest research on continual learning systems
- GitHub Repository - Source code and issue tracking
- HuggingFace Models - Pre-trained teachers
- Evaluation Harnesses - Runtime, reward, and learning measurement scripts