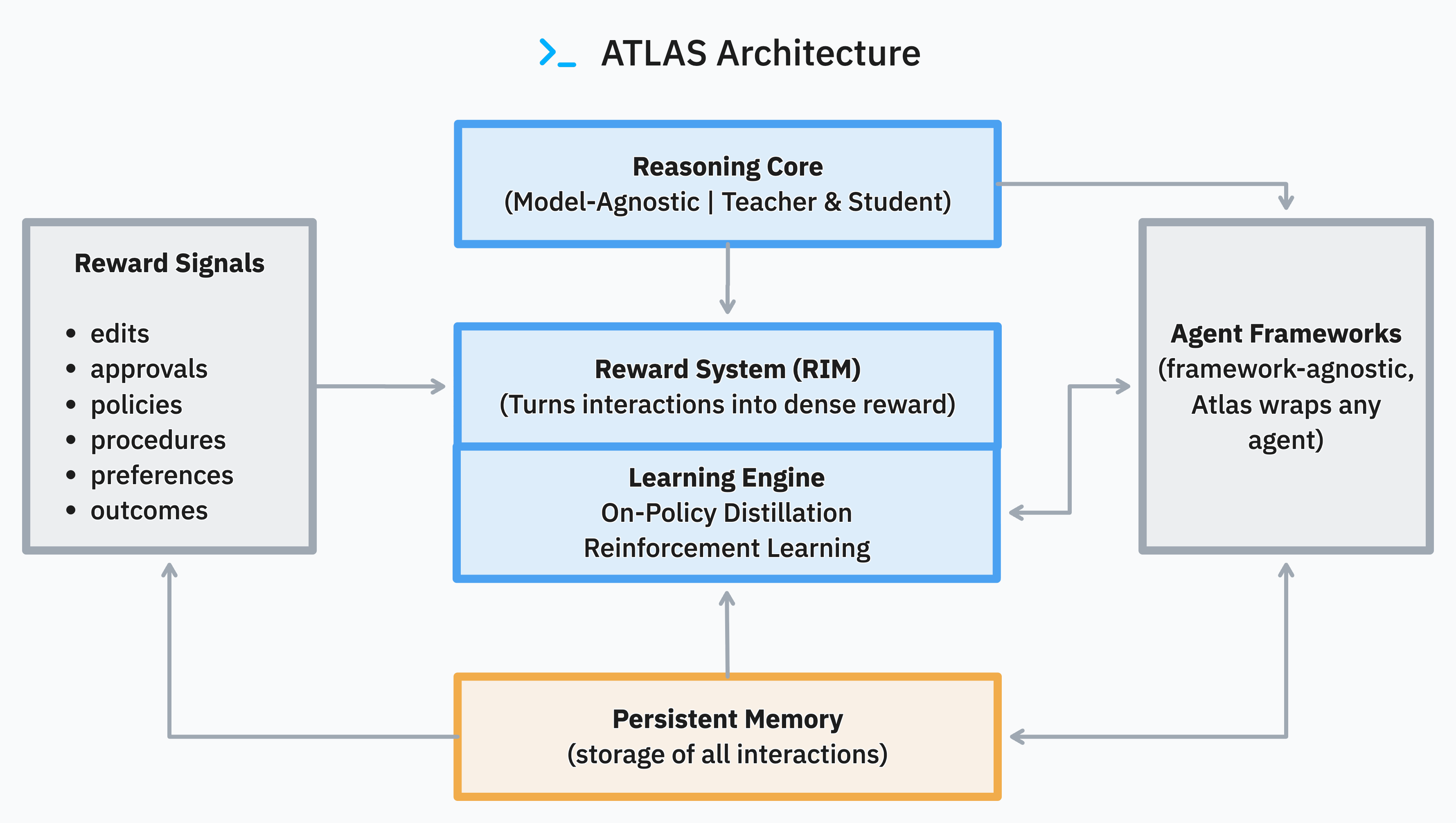
Overview
Generalized Knowledge Distillation (GKD) enables on-policy distillation of Atlas runtime traces into smaller, faster student models. Instead of re-running a full reinforcement-learning cycle, use GKD to compress a reliable teacher checkpoint while staying within the reward-weighted data captured in production.Atlas Training Stack Fit
Problem: Atlas SDK deployments often produce a reliable teacher policy plus verified runtime traces, yet the teacher checkpoint is too large or costly to redeploy, and running the full SFT → GRPO stack again would add days of compute. Solution: Use GKD to transfer the teacher’s action distribution to a smaller student directly from the same on-policy traces, reducing latency while respecting the reward-weighted data collected in production. Technical Implementation: The run config (src/atlas_core/configs/recipe/teacher_gkd.yaml) wires the GKD trainer (src/atlas_core/configs/trainer/gkd.yaml) and the Postgres-backed dataset builder in atlas_core.data.gkd. Trace exports match the schema captured in the MCP Tool Learning example, so you can replay identical workloads through distillation or GRPO. For the reinforcement-learning path, see grpo-training.mdx; both flows follow the override patterns documented in the Training Configuration Guide.
Data Flow: Runtime to Training
The GKD training pipeline connects runtime traces to trained models:| Stage | Tool | Input | Output | Time |
|---|---|---|---|---|
| 1. Runtime execution | atlas run | User tasks | Episode traces in Postgres | Minutes |
| 2. Export traces (optional) | arc-atlas | Postgres episodes | JSONL dataset | Minutes |
| 3. GKD training | atlas-core train recipe@_global_=teacher_gkd | JSONL or Postgres traces | Distilled checkpoint | 4-8 hours |
| 4. Deploy checkpoint | Update teacher_model_name_or_path in config | Trained model | Production teacher | Minutes |
No traces yet? Run the Adaptive Tool Use example to generate training data, or see SDK Export Traces to populate your database.
Runtime traces flow from SDK execution to Postgres storage to GKD training to deployed teacher models
Core Capabilities
GKD handles multi-turn traces directly from Postgres, applies the same tokenization and augmentation stack that GRPO uses, and records baseline-comparison telemetry (success delta and token efficiency) in WandB for side-by-side evaluation with other Atlas trainers. The same Hydra overrides that configure the GRPO pipeline apply here, so swapping between distillation and reinforcement learning becomes a config change rather than a separate code path.When to Use GKD vs GRPO
| Criterion | GKD | GRPO |
|---|---|---|
| Data source | Atlas runtime traces | Interactive environment |
| Compute cost | Low (supervised + KL) | High (PPO + rollouts) |
| Speed | Fast (single pass) | Slow (multi-epoch) |
| Best for | Distill teacher → student | Train from scratch with RL |
| Training time | Hours | Days |
Quick Start
Prerequisites
Before running GKD training, verify your environment:Clone Atlas Core Repository
GKD training requires the full Atlas Core repository (not just the SDK):
Set Database URL (Optional)
GKD training can load traces from Postgres. Set your connection string if using database access:
Using JSONL exports instead? Skip this step and provide
dataset_path in your config.Run First Training Job
Once prerequisites are met, start a minimal GKD run:First run? Add
trainer.max_steps=100 to complete a smoke test in 15-20 minutes instead of hours.Verify Success
Check training progress:Custom metrics like
metrics/success_delta and metrics/token_reduction_pct are logged to WandB/TensorBoard, not in the console training logs.metrics/success_delta- Should be positive (student improving over baseline)metrics/token_reduction_pct- Target: >20% token savingsmetrics/meets_target- Should betruewhen both success and token targets met
| Metric | Target | Meaning |
|---|---|---|
| Training Loss | <1.0 | Student learning teacher distribution |
| KL Divergence | 0.3-0.6 | Balanced teacher/student alignment |
| Success Delta | >0 (positive) | Student improves over baseline |
| Token Reduction | >20% | Smaller model is more efficient |
Qwen/Qwen2.5-14B-Instruct teacher and Qwen/Qwen2.5-7B-Instruct student) are used by scripts/validate_gkd.py to measure the GSM8K lift before scaling to customer traces.
Hydra composes the trainer from src/atlas_core/configs/recipe/teacher_gkd.yaml, which overrides _global_.trainer=gkd and the shared data presets documented in Training Configuration. Override any field inline (for example trainer.learning_key) using the same syntax shown in the GRPO guide.
Running the command streams Atlas runtime traces directly from Postgres (the same database you populate with arc-atlas --database-url postgresql://... --include-status approved --output traces/runtime.jsonl), fine-tunes the 7B student to mimic the 14B teacher, logs the Baseline Comparison metrics (success delta and token reduction) to WandB, and writes checkpoints into outputs/gkd/. If you prefer to operate on JSONL exports, point the dataset adapter at the CLI output; both paths preserve the SDK schema so Atlas Core sees identical conversation records. For a step-by-step walkthrough of exporting traces, running the validation script, and reading the metrics file, see the Developer Example: Running GKD.
Configuration Files
GKD training uses two main config files. The trainer config (src/atlas_core/configs/trainer/gkd.yaml) houses the GKD-specific hyperparameters (lmbda, beta, temperature) plus database connectivity and general training settings. The run config (src/atlas_core/configs/recipe/teacher_gkd.yaml) specifies student and teacher checkpoints, the Baseline Comparison reference metrics, and the output/logging targets.
Cross-Tokenizer Alignment
Issue #45 introduced native support for cross-tokenizer distillation. Two new trainer parameters control the behavior:align_teacher_template(default:true) – when enabled, Atlas captures the raw prompt/completion text for every dataset row, re-renders the conversation with the teacher tokenizer, and computes teacher logprobs in the teacher’s chat template before applying the KL term. Disable it only when the student and teacher share identical tokenizers or when you need to reproduce legacy runs.teacher_tokenizer_name_or_path(optional) – override when the tokenizer lives at a different path thanteacher_model_name_or_path(for example, PEFT adapters or custom checkpoints).
scripts/validate_gkd.py:
Key Parameters
GKD Parameters
lmbda (On-Policy Fraction)
Set lmbda to 1.0 when the student should generate every response and receive teacher guidance token by token; this setting keeps the run fully on-policy and matches the configuration we use for the GSM8K validation sweeps. A mid-range value such as 0.5 mixes teacher- and student-generated continuations when you want to temper exploration, while 0.0 reverts to supervised distillation. Start with 1.0 and only back off when trace quality is noisy or you need consistency with earlier supervised checkpoints (Issue #40 recommendation).
beta (KL Divergence Balance)
beta tunes the interpolation inside the generalized Jensen-Shannon Divergence. Push it toward 0.0 to emphasize the teacher distribution (forward KL), move toward 1.0 to penalize deviations from the student distribution (reverse KL), and stay at the default 0.5 for a balanced view. Start at 0.5, then sweep ±0.2 once you have telemetry on success deltas and token savings.
temperature
Sampling temperature controls how aggressively the student explores during generation. Values around 0.9 yield more diverse reasoning chains and match the public validation scripts; dropping to 0.5–0.7 tightens answers when traces have deterministic formats. Stick with 0.9 for early runs and lower it only after observing long completions or oscillating eval loss.
Database Filtering
min_reward
Minimum session reward threshold for training data:
learning_key
Filter traces by task type:
null to use all traces.
Baseline Comparison Metrics
Track distillation quality against baseline:metrics/success_delta, metrics/token_reduction_pct, and metrics/meets_target alongside loss curves so you can judge whether the distilled checkpoint clears your success and token budgets without exporting separate spreadsheets.
Example Configurations
High-Quality Distillation
For maximum quality, use higher reward threshold and more epochs:Fast Iteration
For rapid experimentation:Task-Specific Distillation
For a specific workflow:Monitoring Training
WandB Metrics
The trainer streamstrain/loss, train/learning_rate, eval/loss, eval/success_rate, eval/avg_tokens, and the Baseline Comparison trio (metrics/success_delta, metrics/token_reduction_pct, metrics/meets_target) to WandB so you can correlate convergence with task-level improvements without building a custom dashboard.
Command Line Output
Training Telemetry Example
Recent GSM8K validation runs illustrate what a healthy loop looks like. With the stock configuration (lmbda=1.0, temperature=0.9, min_reward=0.8, learning_rate=2e-5, max_steps=500), training loss fell from 0.0676 to 0.0294 within 500 steps (epoch ≈0.21) and evaluation loss followed closely (0.0437 → 0.0397 → 0.0394). Gradient norms stayed between 0.88 and 1.70 and the entire run finished in 11h 45m on a single DGX Spark. When we extended the same configuration across the full GSM8K export, evaluation loss continued drifting downward toward 0.0341 while gradients remained below 1.3 even as the learning rate decayed to 7e-6. Use those ranges as a reference point—if training loss stalls above ~0.04 with steady gradients, tighten min_reward or lower temperature before changing optimizer settings.
Troubleshooting
Issue: “No conversations found in database”
Cause: Database connectivity or filtering too strict. Solutions: ConfirmATLAS_DB_URL points to the right cluster, run atlas.training_data.get_training_sessions() to verify rows are available, temporarily lower trainer.min_reward, and clear learning_key to widen the task filter while debugging.
Issue: “Out of memory (OOM) during training”
Cause: Student + teacher models exceed GPU memory. Solutions: Reduce the effective batch by settingper_device_train_batch_size=2 with gradient_accumulation_steps=8, keep gradient checkpointing enabled (default), load the teacher in 8-bit via teacher_model_init_kwargs.load_in_8bit=true, or drop to a smaller teacher checkpoint when the hardware budget is tight.
Issue: “Metrics not improving”
Possible causes and solutions: If metrics stall, first extend the schedule (num_train_epochs: 5) so the loss has room to decay, then sweep beta toward 0.3 or 0.7 to change the KL emphasis. Raising min_reward to 0.85 filters out marginal traces, and if the student remains constrained, move to a larger base checkpoint before adjusting optimizer settings.
Issue: “Training too slow”
Capmax_steps (for example 500 instead of multi-epoch sweeps), relax eval_steps to 200 to avoid constant validation passes, or set limit: 5000 on the dataset loader when you only need a smoke test.
Advanced Topics
Continual Learning with GKD
To preserve existing skills while distilling new knowledge:Multi-Stage Distillation
Distill progressively smaller models:Integration with Arc-CRM-Benchmark
For Stage 3 evaluation (Issue #42):API Reference
AtlasGKDTrainer
Dataset Functions
Baseline Comparison Metrics
Next Steps
Review the Configuration Reference for override syntax, compare with the reinforcement-learning workflow described ingrpo-training.mdx, and validate distilled checkpoints with the Evaluation Harnesses.
Status and Contributions
GKD support in Atlas Core remains beta. We’re building expanded dataset filters, staged teacher → student schedules, and deeper telemetry hooks; track progress in Issue #40. Contributions are welcome—open a PR with trace snippets, Hydra overrides, or MCP-focused repro steps (the MCP Tool Learning example is the easiest shared workload) so we can iterate on the trainer together. For a qualitative look at how teams alternate between fast validation runs and longer reliability sweeps, see the ongoinggkd_two_gear_gkd_blog_draft.md research note.