Overview
Online optimization allows you to enhance any model’s performance on specific tasks in just 2 hours using API-based training. This approach leverages pre-trained ATLAS teachers and reflective mutation for rapid improvement.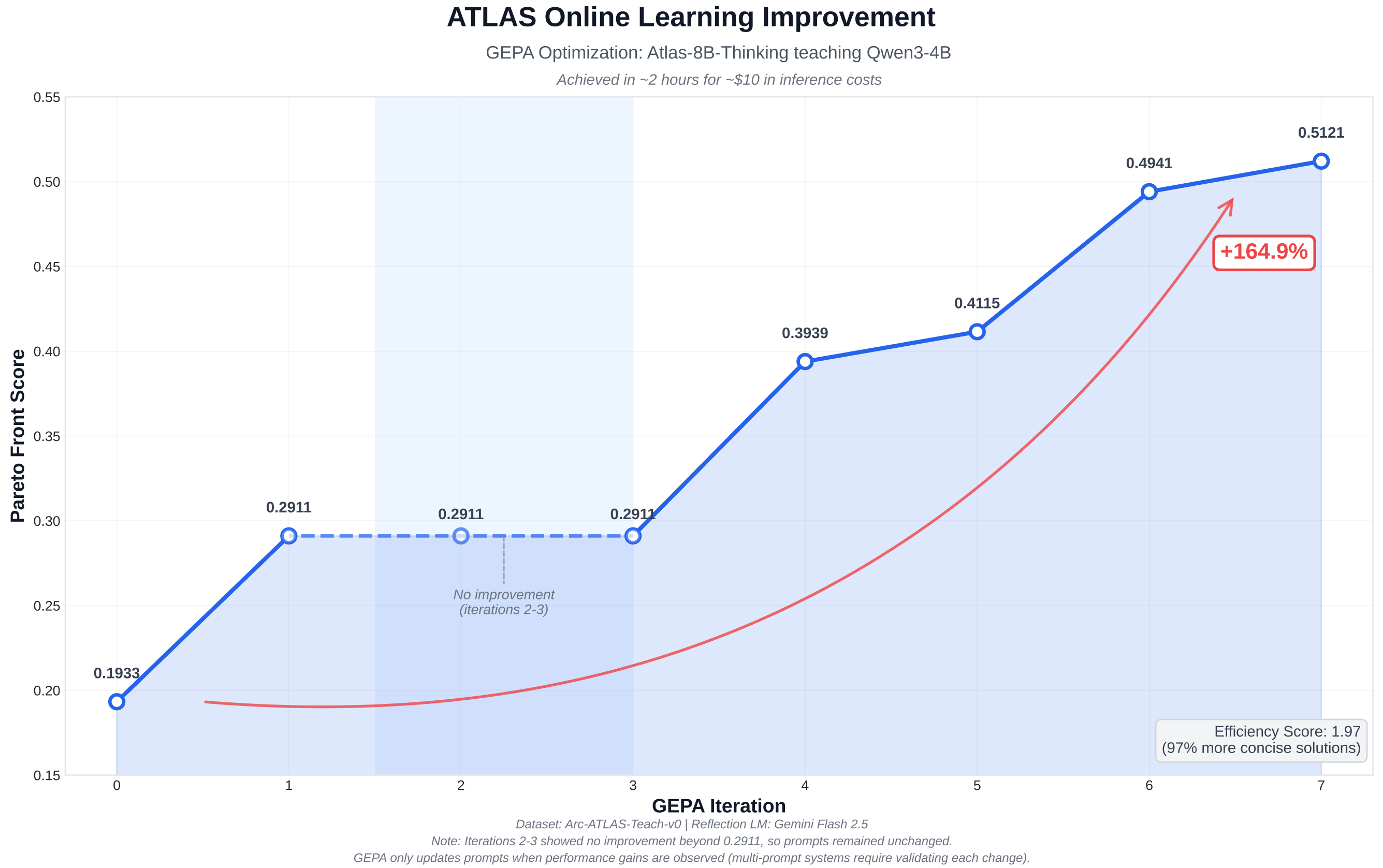
Prerequisites
- OpenAI API key (for optimization agent)
- Pre-trained ATLAS teacher model
- Task-specific evaluation data
- ~$10 in API credits
Quick Start
1
Set Up Environment
Configure API credentials and install dependencies:
Online optimization uses GPT-4 for reflective mutation. Ensure your API key has sufficient credits.
2
Prepare Task Data
Create evaluation samples for your specific task:
Use representative samples that cover edge cases. Quality matters more than quantity.
3
Run Online Optimization
Execute the optimization script:The optimization process:
- Evaluates baseline performance
- Generates teaching variations
- Tests improvements
- Creates skill capsules
4
Deploy Optimized Model
Use the enhanced teaching strategies:
Optimization Algorithm
Reflective Mutation Process
The online optimization uses reflective mutation to evolve teaching strategies:Performance Tracking
Monitor optimization progress in real-time:Configuration Options
Optimization Parameters
Task-Specific Configurations
Advanced Techniques
Skill Composition
Combine multiple optimized skills:Continuous Learning
Implement online learning in production:A/B Testing Strategies
Test optimized strategies in production:Monitoring and Debugging
Real-time Monitoring
Track optimization metrics:Debugging Failed Optimizations
Optimization Not Converging
Optimization Not Converging
Problem: Score plateaus earlySolutions:
High API Costs
High API Costs
Problem: Exceeding budgetSolutions:
Poor Generalization
Poor Generalization
Problem: Overfitting to samplesSolutions:
Cost Analysis
Typical costs for online optimization:| Task Complexity | Iterations | API Calls | Estimated Cost |
|---|---|---|---|
| Simple | 50 | ~500 | $2-3 |
| Moderate | 100 | ~1500 | $5-8 |
| Complex | 200 | ~3000 | $10-15 |
| Expert | 500 | ~7500 | $25-35 |