Abstract
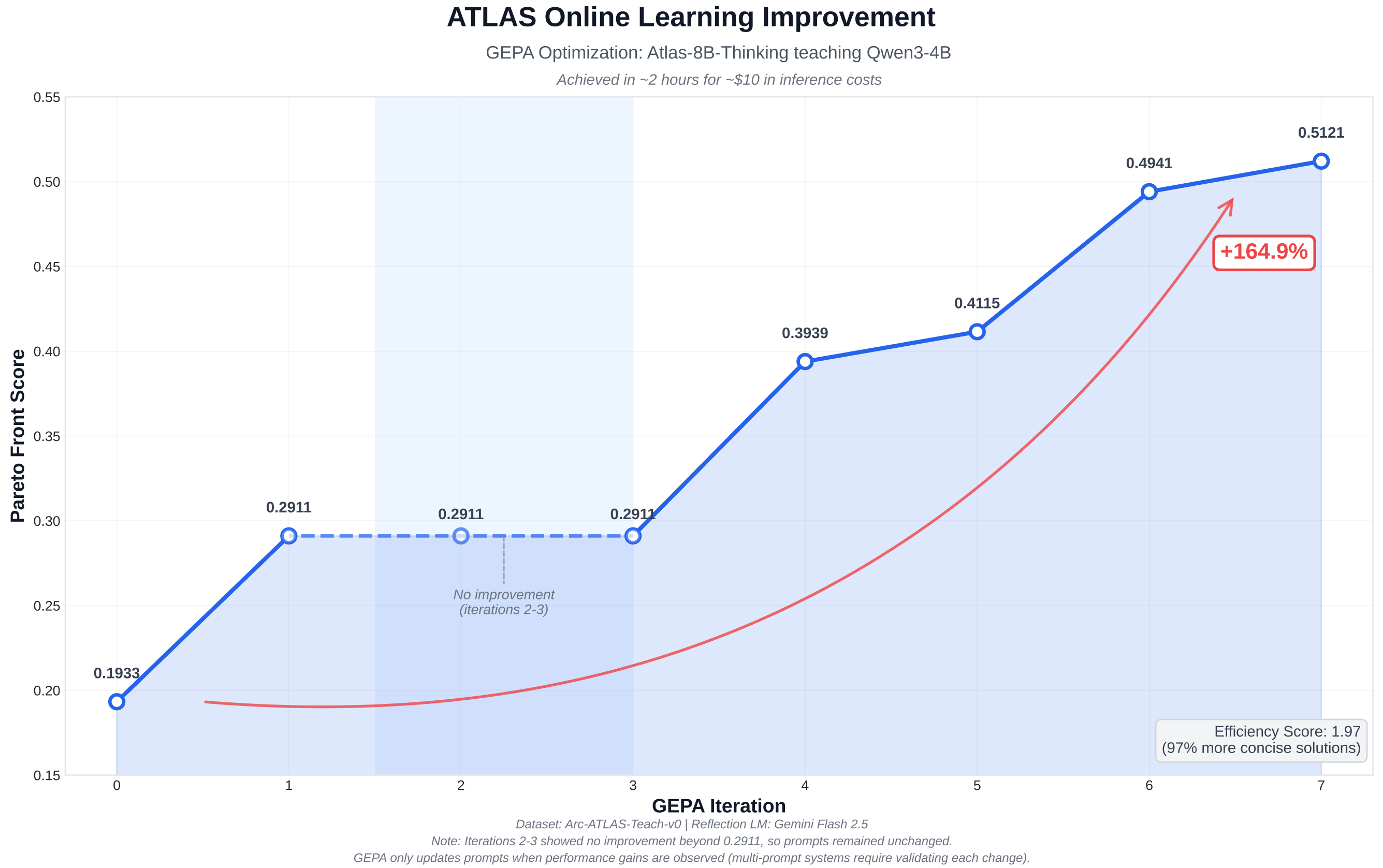
This case study demonstrates the power of layering a hyper-efficient online optimization process (GEPA) on top of a powerful, RL-trained foundation model. By using agemini/gemini-flash-2.5 reflection agent to evolve the prompts of our ATLAS-8B-Thinking teacher model, we achieved a +165% performance improvement on the student model in approximately 2 hours and at a cost of only ~$10 in API inference.
+165% Performance
Measured by the increase in the Pareto front score, reflecting robust and diverse solutions.
~2 Hours to Optimize
Rapid adaptation without the need for expensive, long-running training jobs.
The Hybrid Architecture: Offline RL + Online Optimization
This experiment showcases a hybrid approach that combines the best of offline and online learning:-
Offline RL Foundation (ATLAS): The
ATLAS-8B-Thinkingteacher model is first trained offline using our Reinforced Continual Learning (RCL) process. This builds a deep, generalizable foundation of reasoning and pedagogical skills. - Online Optimization (GEPA): We then use a “reflection agent” to analyze student failures on a live task and propose targeted “reflective mutations” to the teacher’s prompts. This rapidly specializes the teacher for the specific task domain.